# ============================================================
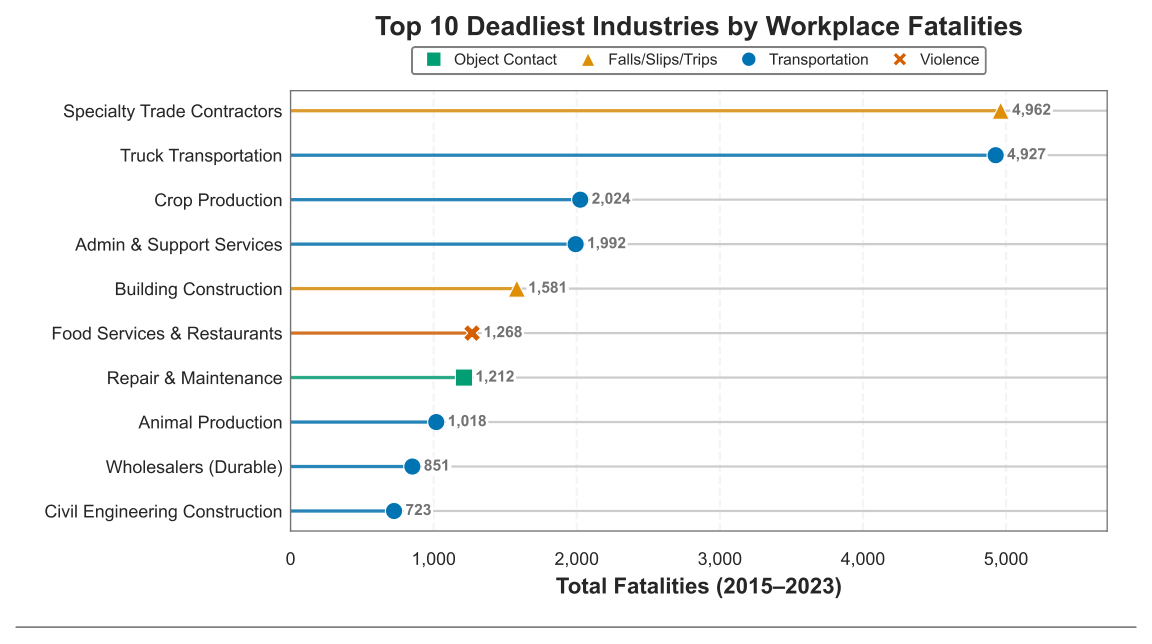
# Visualization 4: Top 10 Deadliest Industries (Lollipop Chart)
# ============================================================
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
import seaborn as sns
# Wong colorblind-safe palette (Nature Methods 2011)
WONG = sns.color_palette('colorblind')
ANN_GRAY = '0.45'
FALLBACK_GRAY = '#999999'
# Map each cause to a Wong palette color
CAUSE_COLORS = {
'Transportation incidents': WONG[0], # Blue
'Falls slips trips': WONG[1], # Orange
'Contact with objects or equipment': WONG[2],# Green
'Violent Acts by Persons or Animals': WONG[3],# Red
'Exposure to Harmful Substances or Environments': WONG[4],# Purple
'Explosions and Fires': WONG[5], # Brown
}
# --- Accessibility: distinct shapes for B&W printing ---
CAUSE_MARKERS = {
'Transportation incidents': 'o', # Circle
'Falls slips trips': '^', # Triangle
'Contact with objects or equipment': 's', # Square
'Violent Acts by Persons or Animals': 'X', # X-mark
'Exposure to Harmful Substances or Environments': 'D', # Diamond
'Explosions and Fires': 'P', # Plus
}
CAUSE_SHORT = {
'Transportation incidents': 'Transportation',
'Falls slips trips': 'Falls/Slips/Trips',
'Contact with objects or equipment': 'Object Contact',
'Violent Acts by Persons or Animals': 'Violence',
'Exposure to Harmful Substances or Environments': 'Harmful Exposure',
'Explosions and Fires': 'Explosions/Fires',
}
NAME_MAP = {
'Specialty Trade Contractors': 'Specialty Trade Contractors',
'Truck Transportation': 'Truck Transportation',
'Crop Production': 'Crop Production',
'Administrative And Support Services': 'Admin & Support Services',
'Construction Of Buildings': 'Building Construction',
'Food Services And Drinking Places': 'Food Services & Restaurants',
'Repair And Maintenance': 'Repair & Maintenance',
'Animal Production And Aquaculture': 'Animal Production',
'Merchant Wholesalers, Durable Goods': 'Wholesalers (Durable)',
'Heavy And Civil Engineering Construction': 'Civil Engineering Construction',
}
# Load and deduplicate BLS data includes overlapping NAICS levels
# truncate to 3-digit and dedup to avoid double-counting fatalities.
df = pd.read_csv('data/Dangerous Jobs.csv')
df = df.dropna(subset=['NAICS'])
# Can't just filter to 3-digit rows some fatalities only exist at
# 4,5,6 digit level. Truncate all codes to 3 digits instead.
df['NAICS_3'] = (
df['NAICS'] // 10 ** (df['NAICS'].apply(
lambda x: len(str(int(x)))) - 3)
).astype(int)
df = df.drop_duplicates(subset=['NAICS_3', 'Cause', 'Year'])
# Total fatalities per industry - top 10
totals = (
df[df['Cause'] == 'Total.Fatalities']
.groupby('NAICS_3')['Fatalities']
.sum()
.sort_values(ascending=False)
.head(10)
)
# Map NAICS_3 -> MajorGroup name
naics_names = (
df[['NAICS_3', 'MajorGroup']]
.drop_duplicates(subset=['NAICS_3'])
.set_index('NAICS_3')['MajorGroup']
)
# Dominant cause per industry
causes = df[df['Cause'] != 'Total.Fatalities']
by_cause = causes.groupby(
['NAICS_3', 'Cause'])['Fatalities'].sum().reset_index()
dominant = by_cause.loc[
by_cause.groupby('NAICS_3')['Fatalities'].idxmax()]
dominant_map = dominant.set_index('NAICS_3')['Cause']
# Build plot data (reversed so #1 at top)
plot_naics = totals.index.tolist()[::-1]
plot_vals = [totals[n] for n in plot_naics]
plot_labels = [NAME_MAP.get(naics_names[n], naics_names[n])
for n in plot_naics]
plot_colors = [CAUSE_COLORS.get(dominant_map[n], FALLBACK_GRAY)
for n in plot_naics]
plot_markers = [CAUSE_MARKERS.get(dominant_map[n], 'o')
for n in plot_naics]
# Chart
fig, ax = plt.subplots(figsize=(7, 4))
fig.patch.set_facecolor('white')
ax.set_facecolor('white')
y_pos = range(len(plot_naics))
# Stems
ax.hlines(y=y_pos, xmin=0, xmax=plot_vals,
color=plot_colors, linewidth=1.5, alpha=0.8)
# Unique marker per cause for B&W accessibility
for xi, yi, ci, mi in zip(plot_vals, y_pos, plot_colors, plot_markers):
ax.scatter(xi, yi, color=ci, marker=mi, s=60,
zorder=3, edgecolors='white', linewidth=0.5)
# Value labels
for i, (val, color) in enumerate(zip(plot_vals, plot_colors)):
ax.text(val + 80, i, f'{val:,.0f}', va='center',
fontsize=7, color=ANN_GRAY, fontweight='bold',
bbox=dict(facecolor='white', edgecolor='none', pad=0.8))
# Y-axis white bbox so grid lines don't cross through labels
ax.set_yticks(list(y_pos))
ax.set_yticklabels(plot_labels, fontsize=8)
for lbl in ax.get_yticklabels():
lbl.set_bbox(dict(facecolor='white', edgecolor='none', pad=1.5))
# X-axis
ax.xaxis.set_major_formatter(
mticker.FuncFormatter(lambda x, _: f'{int(x):,}'))
ax.set_xlabel('Total Fatalities (2015\u20132023)',
fontsize=10, fontweight='bold')
ax.set_xlim(0, max(plot_vals) * 1.15)
ax.tick_params(axis='x', labelsize=8)
# Title
ax.set_title(
'Top 10 Deadliest Industries by Workplace Fatalities',
fontsize=12, fontweight='bold', pad=25)
# Grid only between the data area, not behind labels
ax.grid(axis='x', alpha=0.2, linestyle='--')
ax.set_axisbelow(True)
# Border around the plot area
for spine in ax.spines.values():
spine.set_visible(True)
spine.set_edgecolor(ANN_GRAY)
spine.set_linewidth(0.6)
ax.tick_params(axis='y', length=0)
# Legend
used_causes = sorted(set(dominant_map[n] for n in plot_naics))
handles = [
plt.Line2D([0], [0], marker=CAUSE_MARKERS[c], color='w',
markerfacecolor=CAUSE_COLORS[c], markersize=7,
label=CAUSE_SHORT.get(c, c))
for c in used_causes
]
ax.legend(handles=handles, loc='lower center',
bbox_to_anchor=(0.5, 1.02),
ncol=len(used_causes), fontsize=7,
framealpha=0.9, edgecolor=ANN_GRAY,
handletextpad=0.3, columnspacing=1.0)
plt.tight_layout()
fig.add_artist(plt.Line2D([0, 1], [0, 0], transform=fig.transFigure,
color='0.5', linewidth=0.8))
plt.show()