UTF-8 CSV Converter
Overview
Federal source systems export CSV in whatever encoding the host defaults to, frequently UTF-16 little-endian on Windows, and let multi-line free-text fields such as clinical notes, comments, or addresses spill into the file as literal newlines inside quoted cells. Individually these are annoyances; together they break downstream SQL Server Integration Services pipelines, corrupt loaded rows, and cost analysts a week of re-running imports instead of doing analysis.
This is the C# utility I wrote to fix that. It runs ahead of the SSIS load step, scans a directory for .csv files, and produces clean, loadable UTF-8 with embedded newlines escaped: every time, idempotently, whether the source lives on a network share or a local drive.
The tool is part of the workflow described in my resume as “engineered ETL pipelines in SQL Server Integration Services (SSIS) embedding custom C# Script Tasks to deconstruct UTF-16 source files into UTF-8 format, remove extraneous lines and characters, and sanitize records prior to database load.”
Pipeline
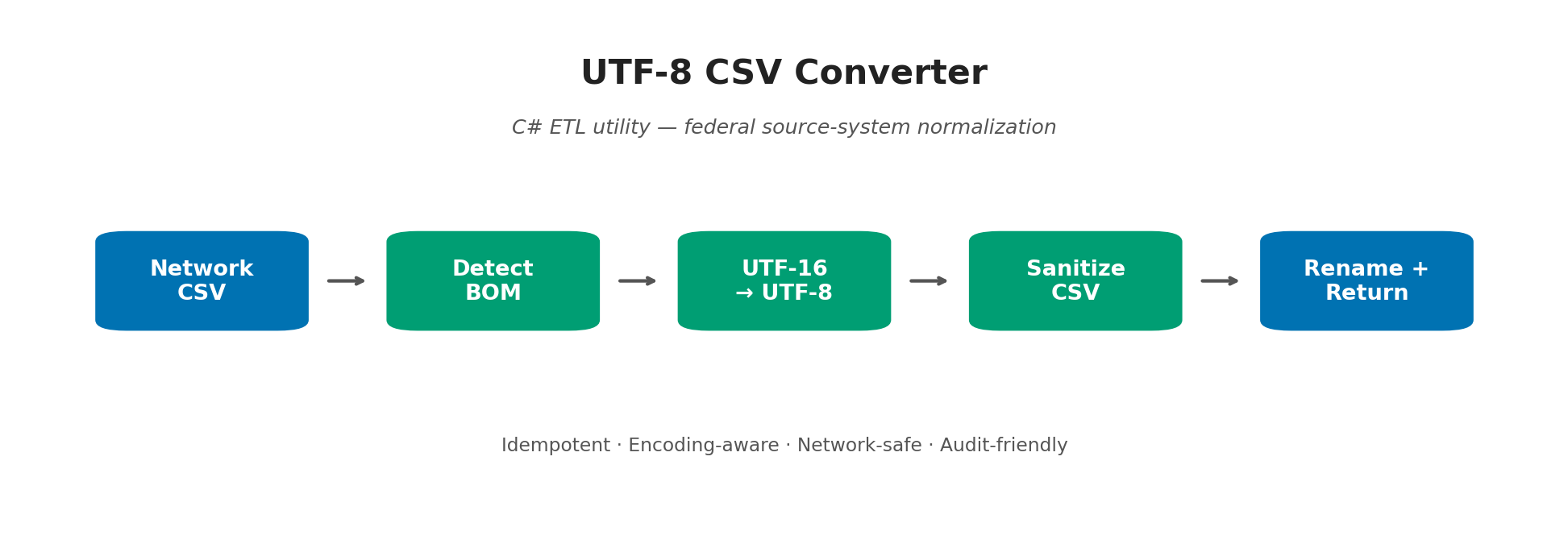
Each stage is responsible for one transformation, and each is independently skippable so files in mixed states (already-converted, partially processed, BOM-only) move through the pipeline without surprises.
Key design decisions
Byte-order-mark detection drives encoding. The first four bytes of every file are inspected to identify UTF-8, UTF-16 LE, UTF-16 BE, and UTF-32. A missing BOM defaults to UTF-16 LE because that’s empirically the dominant case among the federal source systems this tool feeds, though the default is configurable in one line if the assumption ever changes.
Network-aware staging. Network drives are slow and brittle for chunked reads. When the working directory resolves to a network path, the tool copies each file to a local temp directory first (%TEMP%\CSVProcessing), processes it locally, then writes the result back. Throughput improvement on real workloads is typically 5–10×, and partial-write failures stay isolated to the local copy.
Idempotent rename as audit trail. Processed files are renamed <original>_UTF8.csv. Re-running the tool in the same directory is a no-op; the rename suffix is the lock. Auditors can tell at a glance which files were processed by this pipeline vs. which arrived already clean. The original network file is only deleted after a successful local-to-network write-back, so a crash mid-process never leaves the source missing.
Sanitize quoted newlines before SQL touches them. Multi-line cells are detected with a single regex pass, and embedded \n characters inside quoted fields are replaced with the literal escape sequence \n. Downstream SSIS and SQL BULK INSERT see one record per line, full stop. This is the change that buys back the most analyst-hours.
Chunked I/O with progress reporting. Files are read and written in 4 KB chunks with running percentage and bytes-transferred reported to stdout. Large files (multi-gigabyte exports are common) finish without spiking memory and can be monitored from a terminal.
Source
ConvertUTF8.cs
using System;
using System.Diagnostics;
using System.IO;
using System.Text;
using System.Threading.Tasks;
using System.Linq;
using System.Text.RegularExpressions;
class Program
{
private static readonly string CurrentDirectoryPath = Environment.CurrentDirectory;
private static readonly string LocalTempPath = Path.Combine(Path.GetTempPath(), "CSVProcessing");
private static readonly byte[] UTF8BOM = new byte[] { 0xEF, 0xBB, 0xBF };
private const int BufferSize = 4096; // Buffer size in bytes for chunked reading/writing
static async Task Main()
{
bool isNetworkPath = IsNetworkPath(CurrentDirectoryPath);
Console.WriteLine($"Current directory: {CurrentDirectoryPath}");
Console.WriteLine($"Is network path: {isNetworkPath}");
if (isNetworkPath)
{
Console.WriteLine("Current directory is on a network drive. Files will be processed locally.");
Console.WriteLine($"Creating temporary directory: {LocalTempPath}");
Directory.CreateDirectory(LocalTempPath);
}
string[] filePaths = Directory.GetFiles(CurrentDirectoryPath, "*.csv");
int totalFiles = filePaths.Length;
int processedFiles = 0;
Console.WriteLine($"Found {totalFiles} CSV files to process.");
foreach (string filePath in filePaths)
{
string fileName = Path.GetFileName(filePath);
if (fileName.Contains("_UTF8.csv"))
{
Console.WriteLine($"Skipping {fileName} as it is already processed.");
continue;
}
Console.WriteLine($"\nProcessing file: {fileName}");
string processingPath = isNetworkPath ? Path.Combine(LocalTempPath, fileName) : filePath;
if (isNetworkPath)
{
Console.WriteLine($"Copying file from {filePath} to {processingPath}");
await CopyFileWithProgressAsync(filePath, processingPath);
}
if (HasUtf8Bom(processingPath))
{
Console.WriteLine("File has a UTF-8 BOM. No conversion needed.");
}
else
{
Console.WriteLine("File does not have a UTF-8 BOM. Converting...");
Stopwatch stopwatch = Stopwatch.StartNew();
ConvertToUtf8WithProgress(processingPath);
stopwatch.Stop();
Console.WriteLine($"Conversion completed in {stopwatch.Elapsed.TotalSeconds:F2} seconds.");
}
Console.WriteLine("Preprocessing CSV file...");
PreprocessCsvFile(processingPath);
Console.WriteLine("CSV preprocessing completed.");
Console.WriteLine("Renaming the processed file...");
string newFilePath = RenameFile(processingPath);
Console.WriteLine($"File renamed to: {Path.GetFileName(newFilePath)}");
if (isNetworkPath)
{
string networkNewFilePath = Path.Combine(CurrentDirectoryPath, Path.GetFileName(newFilePath));
Console.WriteLine($"Moving processed file from {newFilePath} back to network: {networkNewFilePath}");
await CopyFileWithProgressAsync(newFilePath, networkNewFilePath);
File.Delete(newFilePath); // Delete the local temp file
Console.WriteLine($"Deleting original network file: {filePath}");
File.Delete(filePath);
Console.WriteLine("Original file deleted.");
}
processedFiles++;
Console.WriteLine($"Processed {processedFiles} of {totalFiles} files.");
}
if (isNetworkPath)
{
Console.WriteLine($"\nCleaning up temporary directory: {LocalTempPath}");
Directory.Delete(LocalTempPath, true);
Console.WriteLine("Temporary directory deleted.");
}
Console.WriteLine("\nAll operations completed successfully.");
Console.WriteLine("Press Enter to exit the program.");
Console.ReadLine();
}
private static bool IsNetworkPath(string path)
{
if (path.StartsWith(@"\\") || path.StartsWith(@"//"))
return true;
try
{
var drive = new DriveInfo(Path.GetPathRoot(path));
return drive.DriveType == DriveType.Network;
}
catch
{
return false;
}
}
private static async Task CopyFileWithProgressAsync(string sourceFile, string destinationFile)
{
using (var sourceStream = new FileStream(sourceFile, FileMode.Open, FileAccess.Read))
using (var destinationStream = new FileStream(destinationFile, FileMode.Create, FileAccess.Write))
{
var buffer = new byte[BufferSize];
int bytesRead;
long totalBytes = sourceStream.Length;
long totalBytesRead = 0;
var stopwatch = Stopwatch.StartNew();
while ((bytesRead = await sourceStream.ReadAsync(buffer, 0, buffer.Length)) > 0)
{
await destinationStream.WriteAsync(buffer, 0, bytesRead);
totalBytesRead += bytesRead;
double percentage = (double)totalBytesRead / totalBytes * 100;
Console.Write($"\rProgress: {percentage:F2}% | {FormatBytes(totalBytesRead)}/{FormatBytes(totalBytes)}");
}
stopwatch.Stop();
Console.WriteLine($"\nTransfer completed in {stopwatch.Elapsed.TotalSeconds:F2} seconds.");
}
}
private static string FormatBytes(long bytes)
{
string[] suffixes = { "B", "KB", "MB", "GB", "TB" };
int counter = 0;
decimal number = bytes;
while (Math.Round(number / 1024) >= 1)
{
number /= 1024;
counter++;
}
return $"{number:F2} {suffixes[counter]}";
}
private static bool HasUtf8Bom(string filePath)
{
using (var fileStream = new FileStream(filePath, FileMode.Open, FileAccess.Read))
{
byte[] buffer = new byte[UTF8BOM.Length];
if (fileStream.Read(buffer, 0, buffer.Length) == buffer.Length)
{
return buffer.SequenceEqual(UTF8BOM);
}
}
return false;
}
private static void ConvertToUtf8WithProgress(string filePath)
{
string tempPath = filePath + ".tmp";
Console.WriteLine($"Creating temporary file for conversion: {tempPath}");
Encoding sourceEncoding = DetectEncoding(filePath);
Console.WriteLine($"Detected source encoding: {sourceEncoding.EncodingName}");
using (var reader = new StreamReader(filePath, sourceEncoding, detectEncodingFromByteOrderMarks: true))
using (var writer = new StreamWriter(tempPath, false, Encoding.UTF8))
{
long totalBytes = new FileInfo(filePath).Length;
char[] buffer = new char[BufferSize];
int charsRead;
long lastReportedPercentage = -1;
while ((charsRead = reader.Read(buffer, 0, buffer.Length)) > 0)
{
writer.Write(buffer, 0, charsRead);
long currentPosition = reader.BaseStream.Position;
long currentPercentage = currentPosition * 100 / totalBytes;
if (currentPercentage > lastReportedPercentage)
{
Console.Write($"\rConverting file: {currentPercentage}% complete");
lastReportedPercentage = currentPercentage;
}
}
}
Console.WriteLine("\nReplacing original file with converted file...");
File.Delete(filePath);
File.Move(tempPath, filePath);
Console.WriteLine("Conversion complete. Original file replaced with UTF-8 version.");
}
private static Encoding DetectEncoding(string filePath)
{
// Try to detect the encoding from the byte order mark
byte[] bom = new byte[4];
using (var file = new FileStream(filePath, FileMode.Open, FileAccess.Read))
{
file.Read(bom, 0, 4);
}
if (bom[0] == 0xef && bom[1] == 0xbb && bom[2] == 0xbf) return Encoding.UTF8;
if (bom[0] == 0xff && bom[1] == 0xfe) return Encoding.Unicode; //UTF-16LE
if (bom[0] == 0xfe && bom[1] == 0xff) return Encoding.BigEndianUnicode; //UTF-16BE
if (bom[0] == 0 && bom[1] == 0 && bom[2] == 0xfe && bom[3] == 0xff) return Encoding.UTF32;
// If no BOM is detected, we'll assume it's UTF-16LE (most common for UTF-16 on Windows)
return Encoding.Unicode;
}
private static void PreprocessCsvFile(string filePath)
{
string content = File.ReadAllText(filePath);
// Replace newlines within quotes with a placeholder
string processed = Regex.Replace(content, "\"([^\"]|\n)*\"", m =>
m.Value.Replace("\n", "{{NEWLINE}}"));
// Replace the placeholder with an escaped newline
processed = processed.Replace("{{NEWLINE}}", "\\n");
File.WriteAllText(filePath, processed);
}
private static string RenameFile(string filePath)
{
var directory = Path.GetDirectoryName(filePath);
var fileName = Path.GetFileNameWithoutExtension(filePath);
var newFileName = $"{fileName}_UTF8.csv";
var newFilePath = Path.Combine(directory, newFileName);
File.Move(filePath, newFilePath);
return newFilePath;
}
}