YouTube Tracker An Hourly Time-Series Data Pipeline
Python
SQL
PostgreSQL
Data Engineering
Serverless
A serverless data pipeline that crawls YouTube channel and video stats every hour into a PostgreSQL time-series, then answers questions a single scrape never could like which creator’s back catalog is still being algorithmically revived. SQL is the deliverable; pandas just runs the queries.
Overview
YouTube Tracker collects view, like, comment, and subscriber counts for a set of YouTube channels on an hourly schedule and persists them as a time series in PostgreSQL. The same crawler runs two ways: as a local Python script for iteration, and as a DigitalOcean serverless Function on an hourly cron trigger (0 * * * *) in production.
The point of the hourly cadence is the part a one-off scrape can’t reach: velocity. With repeated observations of every video over time, you can ask not just “how many views does this video have” but “how fast is it gaining them right now” and that turns out to surface genuinely surprising behavior in the YouTube recommendation system.
Note
This started as an academic project. The pipeline itself is real and runs on its own the crawler fires hourly on DigitalOcean and writes to a live PostgreSQL database. This page, though, is a static demo: the charts below are drawn from an exported snapshot of those query results, not a live connection to the database. Treat it as a high-level showcase of the tool’s output, not a live dashboard.
Pipeline architecture
YouTube Data API v3
│ channels.list → uploads playlist IDs
│ playlistItems.list (paged, stops at first known video)
│ videos.list (batches of 50) → fresh stats
▼
DigitalOcean Function ── hourly cron (0 * * * *) ──┐
│ one transaction per run │
▼ │
PostgreSQL (managed) │
├─ metadata tables (insert-once, ON CONFLICT DO NOTHING)
└─ snapshot tables (append-only, one row per entity per run)
▼
SQL-first analysis (Jupyter + pandas + matplotlib)The crawler is deliberately frugal with API quota: uploads playlists come back newest-first, so paging stops at the first already-known video on a steady-state run that’s usually a single API call per channel. The whole write phase is wrapped in one transaction: any failure rolls back with no partial state, and a crawl_log row records every run as RUNNING → SUCCESS/PARTIAL/FAILED.
Data model
The schema’s core design decision is the split between immutable-ish metadata and append-only time-series:
channel,video,category,tag,video_tagwritten once withON CONFLICT DO NOTHING; they capture what was seen on first crawl. (The one exception:video.last_seen_atis bumped each run, so a stale value distinguishes “removed from YouTube” from “crawler didn’t run.”)video_snapshot,channel_snapshotappend-only, one row per entity per crawl run, each tied to acrawl_log.log_id. These are the trend tables that make every velocity query possible.
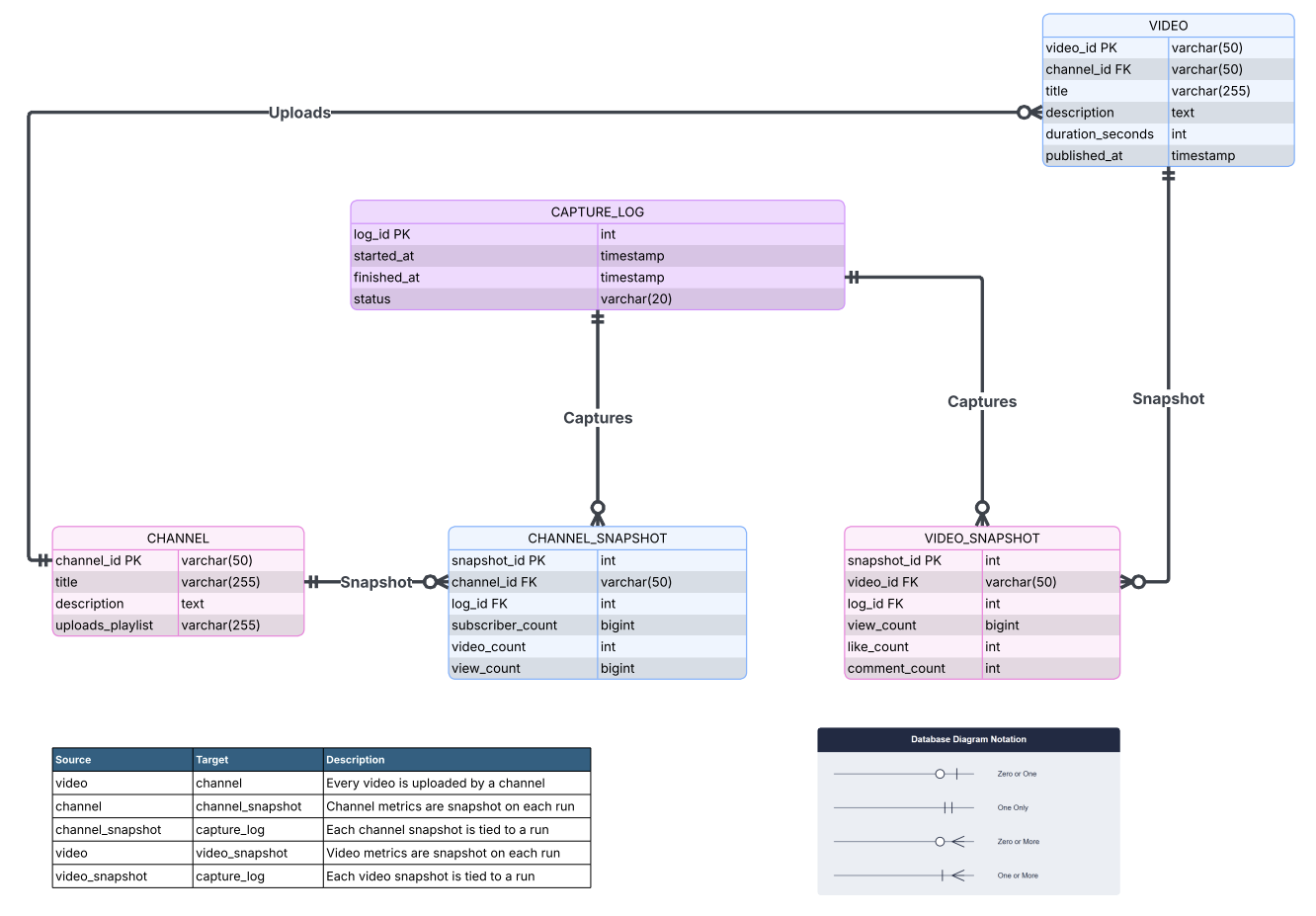
channel_snapshot, video_snapshot) are append-only and reference crawl_log; metadata tables are written once.
Findings
The charts below are interactive hover for exact values, and use the legend to toggle series. They’re drawn client-side from the real aggregated query results.
1 Catalog concentration: how hit-driven is each channel?
Question: What share of a channel’s lifetime views comes from its top 10% of videos? A high number means the channel lives and dies by a few hits; a low number means attention is spread across a deep back catalog.
The query uses DISTINCT ON to grab the latest snapshot per video, NTILE(10) OVER (PARTITION BY channel_id ORDER BY view_count DESC) to cut each channel’s catalog into deciles, then SUM(...) FILTER (WHERE decile = 1) to total just the top decile in one pass.
Finding: Drake is extraordinarily hit-driven 74.5% of his lifetime views come from just his top 10% of videos. Kendrick is similar at 64%. Tech and explainer channels (MKBHD 37%, LTT 40%, TechLinked just 17%) have much flatter distributions: their back catalogs are evergreen and keep accumulating views. Music lives on a handful of bangers; tutorials compound.
2 Content strategy: what lengths does each channel publish?
Question: Does each creator lean Shorts, mid-length, or long-form? A single aggregate pass with COUNT(*) FILTER (WHERE duration_seconds …) buckets every channel’s catalog into YouTube’s conventional length bands without repeated subqueries.
Finding: Each creator has a visibly distinct production strategy. LTT grinds out a deep mix of short- and mid-form (3,435 + 2,595) a back-catalog-first machine. MrBeast is mostly short/mid-form with almost no long content high-effort, digestible episodes. Kendrick is 98 short-form pieces and nothing else music videos only. Switch to Share of catalog to compare strategy independent of catalog size.
3 Views-per-video by category (and the MrBeast effect)
Question: How much attention does the average video earn in each category? Averages level the field between channels with huge catalogs and ones with small focused ones. The query collapses snapshots to latest-per-video, joins to category, and computes both AVG and a true median via PERCENTILE_CONT(0.5).
This is also where the project’s signature outlier shows up. MrBeast contributes ~966 videos to the Entertainment bucket and dominates it so the query was run twice, with and without him. Toggle below:
Source & sample data
The full crawler (local + serverless), schema, migrations, and the SQL-first analysis notebooks are in the repo. A small sample export (youtube_export/) is included so the data shape is browsable note it’s a single-channel, single-snapshot capture for illustration, not the multi-channel time-series the findings above were computed on.
main.py the crawler (local entrypoint)
import os
import re
import time
from datetime import datetime, timezone
import requests
import psycopg2
from psycopg2.extras import execute_values
from dotenv import load_dotenv
# ─── CONFIG ───────────────────────────────────────────────────────────────────
load_dotenv()
API_KEY = os.environ["YT_API_KEY"]
CHANNEL_IDS = [c.strip() for c in os.environ["YT_CHANNEL_IDS"].split(",") if c.strip()]
BASE_URL = "https://www.googleapis.com/youtube/v3"
DB_CONFIG = {
"host": os.environ["DB_HOST"],
"port": int(os.environ.get("DB_PORT", "25060")),
"dbname": os.environ.get("DB_NAME", "defaultdb"),
"user": os.environ.get("DB_USER", "doadmin"),
"password": os.environ["DB_PASSWORD"],
}
# ─── HELPERS ──────────────────────────────────────────────────────────────────
def get(endpoint, params):
params["key"] = API_KEY
r = requests.get(f"{BASE_URL}/{endpoint}", params=params)
r.raise_for_status()
return r.json()
def iso_to_dt(iso_str):
return datetime.fromisoformat(iso_str.replace("Z", "+00:00"))
def duration_to_seconds(duration):
match = re.match(r"PT(?:(\d+)H)?(?:(\d+)M)?(?:(\d+)S)?", duration or "PT0S")
if not match:
return 0
h, m, s = (int(x or 0) for x in match.groups())
return h * 3600 + m * 60 + s
def chunk(lst, size):
for i in range(0, len(lst), size):
yield lst[i:i + size]
# ─── STEP 1: FETCH CHANNEL INFO + UPLOADS PLAYLIST ID ────────────────────────
print("\n── Step 1: Fetching channel info ──────────────────────────────────────")
channel_response = get("channels", {
"part": "snippet,statistics,contentDetails",
"id": ",".join(CHANNEL_IDS)
})
channels = []
uploads_playlists = {} # channel_id → uploads playlist id
category_ids = set()
for item in channel_response.get("items", []):
channel_id = item["id"]
snippet = item["snippet"]
stats = item.get("statistics", {})
uploads_pl_id = item["contentDetails"]["relatedPlaylists"]["uploads"]
uploads_playlists[channel_id] = uploads_pl_id
channels.append({
"channel_id": channel_id,
"title": snippet["title"],
"description": snippet.get("description", ""),
"subscriber_count": int(stats.get("subscriberCount", 0)),
"video_count": int(stats.get("videoCount", 0)),
"view_count": int(stats.get("viewCount", 0)),
"uploads_playlist": uploads_pl_id,
"first_crawled_at": datetime.now(timezone.utc),
})
print(f" Found: {snippet['title']} ({stats.get('videoCount', '?')} videos)")
# ─── STEP 1.5: LOAD VIDEO IDs WE ALREADY HAVE ───────────────────────────────
# Uploads playlists are ordered newest-first, so once we hit a known ID
# every older ID on subsequent pages is also known — we can stop paging.
print("\n── Step 1.5: Loading known video IDs from DB ──────────────────────────")
existing_by_channel = {cid: set() for cid in uploads_playlists.keys()}
try:
with psycopg2.connect(**DB_CONFIG) as conn_ro, conn_ro.cursor() as cur:
cur.execute(
"SELECT channel_id, video_id FROM video WHERE channel_id = ANY(%s)",
(list(uploads_playlists.keys()),),
)
for ch_id, vid_id in cur.fetchall():
existing_by_channel[ch_id].add(vid_id)
for ch_id, vids in existing_by_channel.items():
print(f" channel={ch_id} already tracking {len(vids)} videos")
except Exception as e:
print(f" [warn] DB lookup failed, treating all videos as new: {e}")
# ─── STEP 2: DISCOVER NEW VIDEO IDs, STOP WHEN WE HIT A KNOWN ONE ────────────
print("\n── Step 2: Discovering new video IDs from uploads playlists ───────────")
all_video_ids = []
video_channel_map = {}
for channel_id, playlist_id in uploads_playlists.items():
known = existing_by_channel.get(channel_id, set())
page_token = None
page_count = 0
new_ids = []
hit_known = False
while not hit_known:
params = {
"part": "contentDetails",
"playlistId": playlist_id,
"maxResults": 50,
}
if page_token:
params["pageToken"] = page_token
data = get("playlistItems", params)
page_count += 1
for item in data.get("items", []):
vid_id = item["contentDetails"]["videoId"]
if vid_id in known:
hit_known = True
break
new_ids.append(vid_id)
video_channel_map[vid_id] = channel_id
print(f" channel={channel_id} page={page_count} new={len(new_ids)} hit_known={hit_known}")
if hit_known:
break
page_token = data.get("nextPageToken")
if not page_token:
break
time.sleep(0.2)
# We still want a fresh snapshot for every known video, so map their channel too
for vid_id in known:
video_channel_map[vid_id] = channel_id
channel_ids_total = new_ids + list(known)
all_video_ids.extend(channel_ids_total)
print(f" channel={channel_id} new: {len(new_ids)} existing: {len(known)} total: {len(channel_ids_total)}")
print(f"\n Total video IDs to snapshot: {len(all_video_ids)}")
# ─── STEP 3: FETCH VIDEO DETAILS IN BATCHES OF 50 ────────────────────────────
print("\n── Step 3: Fetching video details ─────────────────────────────────────")
videos = []
snapshots = []
all_tags = {}
video_tag_rows = []
crawl_start = datetime.now(timezone.utc)
errors = 0
for batch in chunk(all_video_ids, 50):
try:
response = get("videos", {
"part": "snippet,statistics,contentDetails",
"id": ",".join(batch)
})
for item in response.get("items", []):
snippet = item["snippet"]
stats = item.get("statistics", {})
content = item.get("contentDetails", {})
video_id = item["id"]
channel_id = video_channel_map.get(video_id, snippet["channelId"])
cat_id = snippet.get("categoryId")
if cat_id:
category_ids.add(cat_id)
videos.append({
"video_id": video_id,
"channel_id": channel_id,
"title": snippet["title"],
"description": snippet.get("description", ""),
"category_id": cat_id,
"duration_seconds": duration_to_seconds(content.get("duration")),
"published_at": iso_to_dt(snippet["publishedAt"]),
"first_crawled_at": datetime.now(timezone.utc),
})
snapshots.append({
"video_id": video_id,
"view_count": int(stats.get("viewCount", 0)),
"like_count": int(stats.get("likeCount", 0)),
"comment_count": int(stats.get("commentCount", 0)),
"captured_at": datetime.now(timezone.utc),
})
for tag in snippet.get("tags", []):
tag_lower = tag.lower()
if tag_lower not in all_tags:
all_tags[tag_lower] = None # tag_id assigned after DB insert
video_tag_rows.append({
"video_id": video_id,
"tag_name": tag_lower,
})
print(f" Processed batch of {len(batch)} | total videos: {len(videos)}")
time.sleep(0.1)
except Exception as e:
print(f" [error] batch failed: {e}")
errors += 1
# ─── STEP 4: FETCH CATEGORIES ─────────────────────────────────────────────────
print("\n── Step 4: Fetching categories ────────────────────────────────────────")
categories = []
if category_ids:
cat_response = get("videoCategories", {
"part": "snippet",
"id": ",".join(category_ids),
"hl": "en_US"
})
categories = [
{"category_id": i["id"], "name": i["snippet"]["title"]}
for i in cat_response.get("items", [])
]
# ─── STEP 5: WRITE TO POSTGRES ────────────────────────────────────────────────
print("\n── Step 5: Writing to PostgreSQL ──────────────────────────────────────")
conn = psycopg2.connect(**DB_CONFIG)
conn.autocommit = False
status = "SUCCESS" if errors == 0 else "PARTIAL"
try:
with conn.cursor() as cur:
# crawl_log first — we need log_id for snapshots
cur.execute(
"""
INSERT INTO crawl_log (started_at, finished_at, videos_crawled, errors, status)
VALUES (%s, %s, %s, %s, %s)
RETURNING log_id
""",
(crawl_start, datetime.now(timezone.utc), len(videos), errors, "RUNNING"),
)
log_id = cur.fetchone()[0]
print(f" crawl_log.log_id = {log_id}")
# categories — insert only if new; never overwrite
if categories:
execute_values(
cur,
"""
INSERT INTO category (category_id, name) VALUES %s
ON CONFLICT (category_id) DO NOTHING
""",
[(c["category_id"], c["name"]) for c in categories],
)
print(f" categories inserted (new only): {cur.rowcount}")
# channels — insert only if new; stats live in channel_snapshot
if channels:
execute_values(
cur,
"""
INSERT INTO channel (
channel_id, title, description, subscriber_count,
video_count, view_count, uploads_playlist, first_crawled_at
) VALUES %s
ON CONFLICT (channel_id) DO NOTHING
""",
[
(
c["channel_id"], c["title"], c["description"],
c["subscriber_count"], c["video_count"], c["view_count"],
c["uploads_playlist"], c["first_crawled_at"],
)
for c in channels
],
)
print(f" channels inserted (new only): {cur.rowcount}")
# channel_snapshot — channel-level trend, one row per channel per run
if channels:
execute_values(
cur,
"""
INSERT INTO channel_snapshot (
channel_id, log_id, subscriber_count, video_count, view_count, captured_at
) VALUES %s
""",
[
(
c["channel_id"], log_id, c["subscriber_count"],
c["video_count"], c["view_count"], c["first_crawled_at"],
)
for c in channels
],
)
print(f" channel_snapshot rows: {len(channels)}")
# videos — insert if new; on conflict, bump last_seen_at so we can
# detect deleted/unavailable videos as a widening gap from NOW()
if videos:
execute_values(
cur,
"""
INSERT INTO video (
video_id, channel_id, title, description, category_id,
duration_seconds, published_at, first_crawled_at, last_seen_at
) VALUES %s
ON CONFLICT (video_id) DO UPDATE SET last_seen_at = EXCLUDED.last_seen_at
""",
[
(
v["video_id"], v["channel_id"], v["title"], v["description"],
v["category_id"], v["duration_seconds"], v["published_at"],
v["first_crawled_at"], v["first_crawled_at"],
)
for v in videos
],
)
print(f" videos upserted (insert or touch last_seen_at): {len(videos)}")
# tags — insert and read back ids (handles ON CONFLICT DO NOTHING returning no row)
if all_tags:
execute_values(
cur,
"INSERT INTO tag (name) VALUES %s ON CONFLICT (name) DO NOTHING",
[(name,) for name in all_tags.keys()],
)
cur.execute(
"SELECT tag_id, name FROM tag WHERE name = ANY(%s)",
(list(all_tags.keys()),),
)
for tag_id, name in cur.fetchall():
all_tags[name] = tag_id
print(f" tags in DB: {len(all_tags)}")
# video_tag bridge
if video_tag_rows:
execute_values(
cur,
"""
INSERT INTO video_tag (video_id, tag_id) VALUES %s
ON CONFLICT DO NOTHING
""",
[(r["video_id"], all_tags[r["tag_name"]]) for r in video_tag_rows],
)
print(f" video_tag rows: {len(video_tag_rows)}")
# video_snapshot — tied to this crawl run
if snapshots:
execute_values(
cur,
"""
INSERT INTO video_snapshot (
video_id, log_id, view_count, like_count, comment_count, captured_at
) VALUES %s
""",
[
(
s["video_id"], log_id, s["view_count"],
s["like_count"], s["comment_count"], s["captured_at"],
)
for s in snapshots
],
)
print(f" video_snapshot rows: {len(snapshots)}")
# finalize crawl_log
cur.execute(
"""
UPDATE crawl_log
SET finished_at = %s,
videos_crawled = %s,
errors = %s,
status = %s
WHERE log_id = %s
""",
(datetime.now(timezone.utc), len(videos), errors, status, log_id),
)
conn.commit()
print(f"\n✓ Done. Committed crawl log_id={log_id}, status={status}\n")
except Exception as e:
conn.rollback()
print(f"\n✗ Transaction rolled back: {e}\n")
raise
finally:
conn.close()Datbase.sql authoritative schema
-- ============================================================
-- YouTube Crawler Schema
-- Database: PostgreSQL
-- ============================================================
-- ── DROP EXISTING TABLES ─────────────────────────────────────
DROP TABLE IF EXISTS video_snapshot CASCADE;
DROP TABLE IF EXISTS channel_snapshot CASCADE;
DROP TABLE IF EXISTS crawl_log CASCADE;
DROP TABLE IF EXISTS video_tag CASCADE;
DROP TABLE IF EXISTS tag CASCADE;
DROP TABLE IF EXISTS video CASCADE;
DROP TABLE IF EXISTS channel CASCADE;
DROP TABLE IF EXISTS category CASCADE;
-- ── CATEGORY ─────────────────────────────────────────────────
CREATE TABLE category (
category_id VARCHAR(10) NOT NULL,
name VARCHAR(100) NOT NULL,
CONSTRAINT pk_category PRIMARY KEY (category_id)
);
-- ── CHANNEL ──────────────────────────────────────────────────
CREATE TABLE channel (
channel_id VARCHAR(50) NOT NULL,
title VARCHAR(255) NOT NULL,
description TEXT,
subscriber_count BIGINT DEFAULT 0,
video_count INT DEFAULT 0,
view_count BIGINT DEFAULT 0,
uploads_playlist VARCHAR(50),
first_crawled_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
CONSTRAINT pk_channel PRIMARY KEY (channel_id)
);
-- ── VIDEO ─────────────────────────────────────────────────────
CREATE TABLE video (
video_id VARCHAR(20) NOT NULL,
channel_id VARCHAR(50) NOT NULL,
title VARCHAR(500) NOT NULL,
description TEXT,
category_id VARCHAR(10),
duration_seconds INT DEFAULT 0,
published_at TIMESTAMPTZ,
first_crawled_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
last_seen_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
CONSTRAINT pk_video PRIMARY KEY (video_id),
CONSTRAINT fk_video_channel FOREIGN KEY (channel_id)
REFERENCES channel (channel_id) ON DELETE CASCADE,
CONSTRAINT fk_video_category FOREIGN KEY (category_id)
REFERENCES category (category_id) ON DELETE SET NULL
);
-- ── TAG ───────────────────────────────────────────────────────
CREATE TABLE tag (
tag_id SERIAL NOT NULL,
name VARCHAR(255) NOT NULL,
CONSTRAINT pk_tag PRIMARY KEY (tag_id),
CONSTRAINT uq_tag UNIQUE (name)
);
-- ── VIDEO_TAG (bridge) ────────────────────────────────────────
CREATE TABLE video_tag (
video_id VARCHAR(20) NOT NULL,
tag_id INT NOT NULL,
CONSTRAINT pk_video_tag PRIMARY KEY (video_id, tag_id),
CONSTRAINT fk_video_tag_video FOREIGN KEY (video_id)
REFERENCES video (video_id) ON DELETE CASCADE,
CONSTRAINT fk_video_tag_tag FOREIGN KEY (tag_id)
REFERENCES tag (tag_id) ON DELETE CASCADE
);
-- ── CRAWL_LOG ─────────────────────────────────────────────────
CREATE TABLE crawl_log (
log_id SERIAL NOT NULL,
started_at TIMESTAMPTZ NOT NULL,
finished_at TIMESTAMPTZ,
videos_crawled INT DEFAULT 0,
errors INT DEFAULT 0,
status VARCHAR(20) NOT NULL DEFAULT 'RUNNING',
CONSTRAINT pk_crawl_log PRIMARY KEY (log_id),
CONSTRAINT chk_crawl_status CHECK (status IN ('RUNNING', 'SUCCESS', 'PARTIAL', 'FAILED'))
);
-- ── VIDEO_SNAPSHOT ────────────────────────────────────────────
CREATE TABLE video_snapshot (
snapshot_id SERIAL NOT NULL,
video_id VARCHAR(20) NOT NULL,
log_id INT,
view_count BIGINT DEFAULT 0,
like_count INT DEFAULT 0,
comment_count INT DEFAULT 0,
captured_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
CONSTRAINT pk_video_snapshot PRIMARY KEY (snapshot_id),
CONSTRAINT fk_snapshot_video FOREIGN KEY (video_id)
REFERENCES video (video_id) ON DELETE CASCADE,
CONSTRAINT fk_snapshot_crawl_log FOREIGN KEY (log_id)
REFERENCES crawl_log (log_id) ON DELETE SET NULL
);
-- ── CHANNEL_SNAPSHOT ──────────────────────────────────────────
CREATE TABLE channel_snapshot (
snapshot_id SERIAL NOT NULL,
channel_id VARCHAR(50) NOT NULL,
log_id INT,
subscriber_count BIGINT DEFAULT 0,
video_count INT DEFAULT 0,
view_count BIGINT DEFAULT 0,
captured_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
CONSTRAINT pk_channel_snapshot PRIMARY KEY (snapshot_id),
CONSTRAINT fk_ch_snapshot_channel FOREIGN KEY (channel_id)
REFERENCES channel (channel_id) ON DELETE CASCADE,
CONSTRAINT fk_ch_snapshot_crawl_log FOREIGN KEY (log_id)
REFERENCES crawl_log (log_id) ON DELETE SET NULL
);
-- ============================================================
-- INDEXES
-- ============================================================
-- Look up all videos for a channel
CREATE INDEX idx_video_channel_id ON video (channel_id);
-- Look up all snapshots for a video, ordered by time
CREATE INDEX idx_snapshot_video_time ON video_snapshot (video_id, captured_at DESC);
-- Look up all snapshots from a crawl run
CREATE INDEX idx_snapshot_log_id ON video_snapshot (log_id);
-- Look up all tags for a video
CREATE INDEX idx_video_tag_video_id ON video_tag (video_id);
-- Full-text search on video titles
CREATE INDEX idx_video_title ON video USING GIN (to_tsvector('english', title));
-- Detect videos that have gone dark (not seen recently = likely deleted)
CREATE INDEX idx_video_last_seen_at ON video (last_seen_at);
-- Look up all channel snapshots for a channel, ordered by time
CREATE INDEX idx_ch_snapshot_channel_time ON channel_snapshot (channel_id, captured_at DESC);
-- Look up all channel snapshots from a crawl run
CREATE INDEX idx_ch_snapshot_log_id ON channel_snapshot (log_id);